# ORC
**Apache ORC (Optimized Row Columnar)** is a **columnar storage file format** designed for high-performance, large-scale data processing, especially within the **Hadoop ecosystem**. It is a self-describing type-aware columnar file format designed for Hadoop workloads. It was developed as part of the **Apache Hive** project and is often used in data processing frameworks such as Apache Hive, Apache Spark, Apache Impala, and others.
The data format is designed and optimized for large streaming reads, but also supports finding required rows quickly. Storing data in a columnar format is popular in analytics as it lets the reader read, decompress, and process only the values that are required for the specific query.\
\
ORC files are type-aware, the writer chooses the most appropriate encoding for the type and builds an internal index as the file is written. Predicate pushdown uses those indexes to determine which stripes in a file need to be read for a particular query and the row indexes can narrow the search to a particular set of 10,000 rows. ORC supports the complete set of types in Hive, including the complex types: structs, lists, maps, and unions.
```python
# Write DataFrame to ORC file
df.write.format("orc").save("/path/to/output")
# Read DataFrame from ORC file
df = spark.read.format("orc").load("/path/to/input")
```
In **Apache Spark**, you can read and write data in ORC format with the following code:
**Using ORC in Apache Spark**
```sql
SELECT * FROM my_table WHERE age > 30;
```
Once the table is created in ORC format, you can query it just like any other Hive table:
**Querying Data in ORC Format**
```sql
CREATE TABLE my_table (
id INT,
name STRING,
age INT
)
STORED AS ORC;
```
In **Apache Hive**, data can be written to ORC format like this:
**Writing Data to ORC in Hive**
#### **How to Use Apache ORC**
* **ORC vs. Parquet**:
* Both **ORC** and **Parquet** are **columnar formats** that offer efficient storage and querying of big data. The main differences are:
* **ORC** tends to provide **better compression ratios** and **faster read performance** for specific workloads (especially for Hive-based systems).
* **Parquet**, on the other hand, is more widely used outside of Hive, and it's better for **interoperability** across a range of tools and languages (Java, Python, etc.).
* **ORC** is optimized for **Hive** and **Impala**, while **Parquet** is used more universally in the **Hadoop ecosystem** and with **Apache Spark**.
* **ORC vs. Avro**:
* **Avro** is a **row-based format** that is great for **serialization** and handling **real-time streaming** of data.
* **ORC** is a **columnar format** and is much more suited for **analytical queries** where performance and storage efficiency are a priority.
* **Avro** is better for **data interchange**, while **ORC** is optimized for analytical workloads in **Hadoop-based systems**.
* **ORC vs. JSON**:
* **JSON** is a **text-based format** that is often used for web and application data. However, it tends to be inefficient for storage and query performance when dealing with large datasets.
* **ORC**, being a **binary columnar format**, is significantly more efficient for **big data processing** in terms of both **storage** and **performance**.
#### **ORC vs. Other Formats**
1. **Data Warehousing**:
* ORC is ideal for **data warehousing** use cases, where structured data needs to be stored efficiently and queried using analytical queries. Its high compression and fast query performance make it a strong choice for managing large datasets in a data warehouse.
2. **Big Data Analytics**:
* ORC is designed for **big data analytics** applications where large volumes of data are processed in distributed environments. It allows for efficient storage and fast querying of large datasets, making it suitable for platforms like Apache Hive, Apache Spark, and Apache Impala.
3. **Log and Event Data Processing**:
* ORC can also be used for storing and processing **log data** and **event streams** that need to be analyzed using big data tools. The compression and query optimization features make it an efficient format for large-scale log analysis.
4. **Data Lakes**:
* ORC is a good choice for **data lakes**, where raw, unstructured, and semi-structured data needs to be stored in a way that is optimized for later processing and analytics. Its ability to handle complex data types and schema evolution is valuable in this context.
5. **IoT and Sensor Data**:
* ORC’s ability to handle **complex, nested data structures** makes it an excellent choice for storing data from **IoT devices** and **sensors**. These types of datasets are often structured in a way that requires efficient columnar storage and retrieval.
#### **Use Cases for Apache ORC**
1. **Improved Storage Efficiency**:
* The columnar format and advanced compression algorithms help **significantly reduce storage requirements**, which makes ORC an excellent choice for large-scale datasets.
* This is especially important for data lakes and data warehouses, where efficient storage of large datasets is essential.
2. **Faster Query Performance**:
* By using a columnar format, **ORC** allows for faster **query processing** because only the relevant columns are loaded into memory during query execution.
* ORC also supports predicate pushdown, which means queries can skip irrelevant data, further improving read performance.
3. **Optimized for Analytical Workloads**:
* ORC is optimized for **analytical queries**, especially those that perform aggregations, filtering, and scanning over large datasets. This makes it ideal for data warehousing and analytics use cases.
4. **Data Integrity and Fault Tolerance**:
* Like other Hadoop-based formats, ORC files are stored in a distributed system, and the **HDFS (Hadoop Distributed File System)** ensures that data is replicated across multiple nodes to ensure **data integrity** and **fault tolerance**.
5. **Compatibility with Big Data Tools**:
* ORC is **natively supported** by a wide range of tools within the Hadoop ecosystem, including **Apache Hive**, **Apache Impala**, **Apache Spark**, and others. It is well integrated into these tools for data storage, processing, and querying.
#### **Benefits of Apache ORC**
1. **Columnar Storage Format**:
* **ORC** uses a **columnar storage format**, meaning that data is stored by columns instead of rows. This design allows for much more efficient storage and query execution, particularly when only specific columns of data are needed.
* This is ideal for **analytical workloads**, where queries often access only a subset of the columns.
2. **High Compression**:
* **ORC** provides very high compression ratios, typically offering **3x to 4x better compression** than row-based formats like **CSV** or **JSON**, and often better than other columnar formats like **Parquet**.
* ORC achieves this high compression using advanced techniques such as **lightweight compression algorithms** and **predicate pushdown** for efficient filtering.
3. **Predicate Pushdown**:
* **Predicate pushdown** is a technique used by ORC to optimize queries. This means that the system can filter data at the storage level before reading it into memory, improving performance by reducing the amount of data processed.
* It allows the database to skip irrelevant blocks or rows based on query filters, speeding up query times significantly.
4. **Support for Complex Data Types**:
* ORC supports complex data types, including **arrays**, **maps**, and **structs**, making it ideal for semi-structured or nested data, which is common in big data environments.
* It provides efficient storage and retrieval of these complex data structures.
5. **Lightweight Indexing**:
* ORC includes **lightweight indexing** for each column, which allows fast lookup and filtering of data without requiring full scans of the file.
* Indexes in ORC allow for quick access to **min/max values** within a column, further optimizing query performance.
6. **Schema Evolution**:
* ORC supports **schema evolution**, which means you can change the structure of the data (e.g., adding new columns) over time without breaking compatibility with the existing data. This is important for large datasets that evolve over time.
7. **Splitting for Parallel Processing**:
* ORC files are **splittable**, meaning large files can be broken into smaller chunks, allowing for parallel processing across distributed computing frameworks such as **Apache Hive**, **Apache Spark**, and **Apache Hadoop**.
* This helps optimize the performance of distributed data processing tasks.
8. **Efficient for Hive**:
* ORC was specifically developed to work with **Apache Hive**, making it a native choice for Hive-based data processing. However, it’s also widely used with other big data processing frameworks such as **Apache Impala** and **Apache Spark**.
#### **Key Features of Apache ORC**
ORC is optimized for both **storage efficiency** and **read performance** in big data environments. It is designed to provide a highly efficient way of storing large volumes of structured data for **analytics workloads** while also being able to handle the challenges of scalability, performance, and fault tolerance.
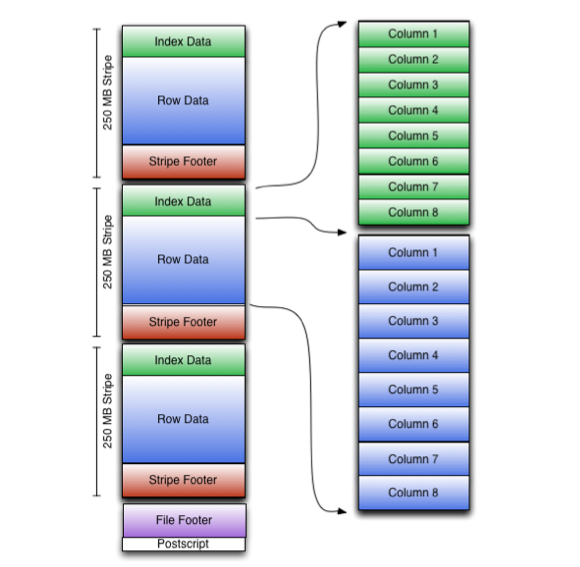
#### **ORC File Structure**
The structure of an ORC file includes the following key components:
1. **File Header**: The magic number at the beginning of the file to identify it as an ORC file.
2. **Row Groups**: Data in ORC is organized into **row groups**, where each row group contains a subset of rows.
3. **Column Chunks**: Each column in a row group is stored separately in **column chunks**.
4. **Stripe**: A group of rows, typically consisting of several row groups, that is written together for storage.
5. **Footer**: Contains metadata, such as the schema and file statistics, which describes the structure of the ORC file.
\
\
source:
#### What is Predicate Pushdown
If you issue a query in one place to run against a lot of data in another place, you end up with a lot of network traffic, which is slow and costly. However if you can “push down” parts of the query to where the data is stored, which filters out most of the data, then reduce network traffic and get faster results.\
\
Read more about ORC spec at [https://orc.apache.org](https://orc.apache.org/specification/ORCv1/)
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://docs.invariant.io/platform/apache-hadoop/hdfs/storage-format/orc.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.